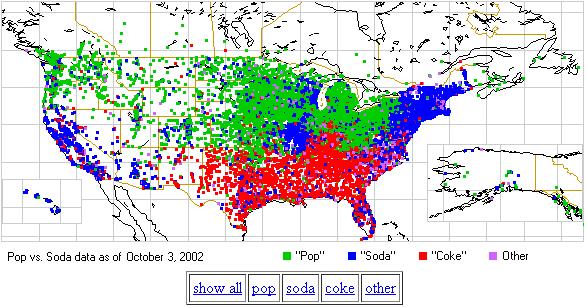
A data scientist at Twitter, Edwin Chen, has used twitter to measure the prevalence of the term ‘soda’ versus ‘pop’ or ‘coke’ across the US, and the world. He compares his work to work done ten years previously on a survey basis, which reveals slight changes over time, but essentially concurs with Chen’s conclusions. In order to arrive at the data set, Chen had to clean the data by removing extraneous references. For example, references to specific drinks – like Coca Cola – were eliminated; and only those references to drinks were included. Then he was left with a pretty accurate picture as represented by Americans who use Twitter – and let’s presume for now that that’s a statistically accurate sample.
Continue reading “Sentiment Analytics and Measuring Legitimacy”


